
When we look at the Resources tab of the .NET Aspire dashboard, we find the State column in the table displayed there. This column shows the current status of each service managed by the .NET Aspire. Ideally, we want each of these services to be shown as Running with the green tick next to it, as the following screenshot demonstrates:

We can check if this process works correctly by making one of the services throw an exception during the startup. If we do this, then the dashboard will look as follows:
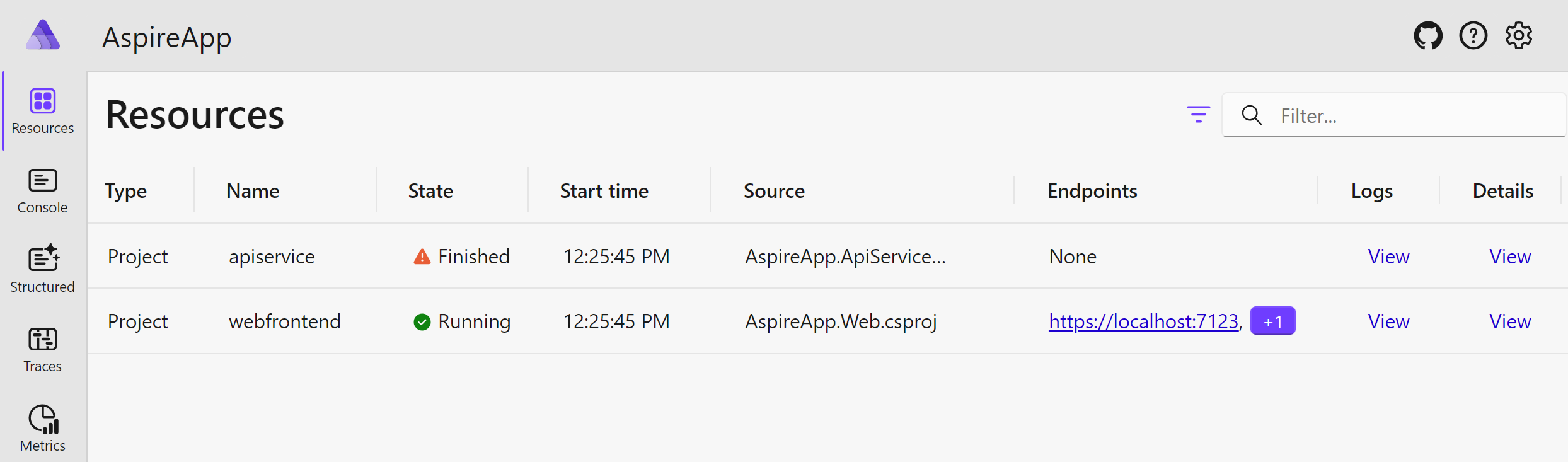
So, the question you may ask is how .NET Aspire knows whether a particular service is running or not? Well, it’s easy. Because Aspire hosts those services, it knows if any of them are still running or not.
However, the State column is very limited in its scope. It will show you that the service is running, but it will not tell you if it’s in an unusable state. For example, it may be running, but it’s so constrained on resources that nothing can access it.
To see if the service is not only running but also happens to be in a health state, you would need a mechanism to perform the so-called health checks. The standard health check mechanism will show you if your app happens to be in either of the following states:
- Healthy: The app is performing all its expected functions.
- Unhealthy: The app is not functioning as expected and may be unable to perform its primary functions.
- Degraded: The application is operational but performing below optimal levels. There might be issues that do not completely halt functionality but impair performance or user experience.
Fortunately, Aspire has an inbuilt mechanism for performing this type of health check. But before we look at it, let’s examine why health checks are important in the first place.
Importance of health checks in a distributed app
Assessing the health of microservices is crucial for maintaining the overall stability, reliability, and performance of a distributed system. Here’s why it’s important for the orchestrator to be involved in this assessment:
- Automatic recovery: By continuously monitoring the health of services in a distributed application, the orchestrator can automatically detect when a service becomes unhealthy or unavailable. This enables the orchestrator to take proactive measures such as restarting failed instances or redistributing the workload to healthy instances without manual intervention.
- Fault tolerance: In a distributed architecture, where services often rely on each other to fulfill requests, the failure of one service can cascade and impact the entire system. By assessing the health of individual services, the orchestrator can identify and isolate failing services, preventing widespread system failures and maintaining fault tolerance.
- Service-level agreements (SLAs) enforcement: Many distributed systems operate under specific SLAs, which define acceptable levels of service availability and performance. The orchestrator, by monitoring the health of microservices, can ensure that these SLAs are met and take corrective actions if necessary to avoid breaching them.
- Dynamic scaling: Health assessment plays a crucial role in dynamic scaling decisions. When the orchestrator detects increased demand or decreased performance, it can automatically scale up instances of healthy services to handle the load and scale down underutilized instances when demand decreases.
- Optimized resource allocation: By continuously evaluating the health of microservices, the orchestrator can optimize resource allocation based on the actual demand and performance of each service. This ensures that resources are efficiently utilized, minimizing costs and maximizing the system’s overall efficiency.
- Enhanced observability: Health assessment provides valuable insights into the overall state of the system. By aggregating health metrics and status information from individual microservices, the orchestrator can provide comprehensive observability and monitoring capabilities, facilitating troubleshooting and performance optimization.
Now, let’s look at how health checks are done in the apps hosted by Aspire.
Enabling health checks inside Aspire apps
Healthcheck is done by the Aspire orchestrator by sending HTTP requests to specific application endpoints. These endpoints generate a specific response to those requests.
We don’t need to create those endpoints manually. We can just register relevant dependencies that will do it for us.
The .NET Aspire starter project has the AddDefaultHealthChecks() extension method inside of its server defaults library. This is what the implementation of this method looks like:
builder.Services.AddHealthChecks()
// Add a default liveness check to ensure app is responsive
.AddCheck("self", () => HealthCheckResult.Healthy(), ["live"]);
Here is what’s happening:
- We are adding the health check logic by invoking the
AddHealthChecks()method on theServicesproperty of thebuilderobject. - We are adding a specific health check by invoking the
AddCheck()method. - Inside this method, we have a Lambda expression that returns the response indicating that our application is healthy.
- We are also adding the
livetag to the response, which we will come back to later.
This is the most simple health check logic we can implement. The health check endpoint will always return the healthy status while the application is running. If something is wrong with the application, the endpoint becomes inaccessible and no such status is returned.
Now, to make it work, we just need to map the appropriate health check endpoints.
Mapping health check endpoints
To map the health check to appropriate HTTP endpoints, we have the MapDefaultEndpoints() method. This method is invoked in the middleware of all HTTP-enabled applications hosted by Aspire. It is used for adding any default endpoints to the applications, including the health check endpoints. The health check endpoints are added by invoking the MapHealthChecks() method on the app object. This is how it’s invoked:
app.MapHealthChecks("/health");
This is a pretty standard way of registering the /health path as the health check endpoint. But there is also another health check endpoint registration, which looks like this:
app.MapHealthChecks("/alive", new HealthCheckOptions
{
Predicate = r => r.Tags.Contains("live")
});
This time, we are registering the /alive path, which the orchestrator knows about. This endpoint is more complicated. We are not only checking whether we receive the correct response. We are also verifying that the response contains the live tag.
When we registered our health check logic previously, we accounted for both of these scenarios. While we are returning a valid response, we are also returning the live tag.
Monitoring app health in production
If we look closely at the code in the Aspire starter project, we will see the following condition before any endpoints are registered:
if (app.Environment.IsDevelopment())
Does this mean that we only do health checks in the development environment? Well, the answer is no.
We must do health checks in any environment, especially production. Moreover, we would need to use the same endpoints with the same paths. However, the production environment will have caveats.
Because health check endpoints are accessible just like any other public HTTP endpoint, the developers will need to apply appropriate protections to the production version of it. The reason that such examples aren’t included in the standard project template is that each scenario will have its own implementation based on the specific requirements.
On the other hand, since the health check endpoints don’t typically share any sensitive information and merely indicate that the application is alive, the developers may opt to enable the same health check logic in production as they have in the development environment.
Wrapping Up
This concludes the overview of how health check endpoints are registered in the .NET Aspire apps. We will continue our .NET Aspire journey next week by looking at the so-called Aspire components, which is a standard way of adding well-known shared services to Aspire applications. These components may include databases, caches, and message broker connections.
P.S. If you want me to help you improve your software development skills, you can check out my courses and my books. You can also book me for one-on-one mentorship.





